GPT-5.5 for Procurement: OpenAI's Smartest Model Meets Real Workflows
OpenAI just launched GPT-5.5, their most capable model ever. The benchmarks are impressive. But benchmarks don't score supplier proposals, redline contracts, or build category strategies. We ran it against the five procurement workflows that matter most.

What OpenAI shipped and what they're claiming
GPT-5.5 dropped on April 23rd. OpenAI calls it their "smartest and most intuitive model yet," a unified architecture that processes text, images, audio, and video end-to-end. It's available to Plus, Pro, Business, and Enterprise users in ChatGPT, with a 1M-token context window in the API.
The headline numbers from the release:
Source: OpenAI, "Introducing GPT-5.5" →
Notice anything? These are coding benchmarks, agentic task benchmarks, and mathematical reasoning tests. Terminal-Bench measures code execution. OSWorld measures desktop automation. FrontierMath measures advanced mathematical problem-solving. None of them tell you whether GPT-5.5 can score an RFP, find a cross-reference error in a contract, or build a category strategy that a CPO would actually present to the board. If you're a procurement team evaluating which LLM to use for real work, these benchmarks don't help.
That's what we tested. This is a head-to-head AI model comparison for procurement: ChatGPT's GPT-5.5 vs Claude's Opus 4.7 across the five workflows that matter most.
The challenger meets the incumbent
Two weeks ago, we published The Handshake #1, a deep review of Claude Opus 4.7, Anthropic's flagship model. It won 4/5 use cases against its predecessor, scored 183/200, and showed real procurement domain expertise: self-verification, data pre-checking, advisory tone. That's our current benchmark for AI-assisted procurement work.
With GPT-5.5 landing a week later, the obvious question from every procurement team evaluating tools is: does OpenAI's new flagship beat the one we just finished testing? (If you're still figuring out which AI mistakes to avoid, start there.) Both LLMs sit at the top of their respective product lines. Both are positioned for complex professional work. Both cost premium pricing. The comparison writes itself.
We also published a quick comparison on RFP generation last week. Claude scored 85.1 to GPT's 66.9 on a minimal-prompting enterprise CRM RFP. That was a single use case, minimal prompting, quick-fire test. This is the full evaluation: five use cases, dual-mode testing (identical prompts AND optimised prompts), systematic scoring across four dimensions.
Same synthetic data as Issue #1. Same scoring framework. Same evaluator. Different models from different companies.
GPT-5.5 is good. Opus is still better for procurement work.
Opus 4.7 won 186.5 to 178.5, a 4.5% margin. It took four of the five use cases, with one dead tie. But this is not a blowout. The lowest individual score in the entire evaluation was 83.75%, and both models produced usable outputs in every single test. GPT-5.5 is a serious tool for procurement work. It just isn't the best AI for procurement available right now.
The interesting finding isn't "Opus won." It's what each model is specifically good at, and those strengths don't overlap. GPT-5.5 has a clear research and citation advantage that Opus can't match. Opus has structural, verification, and output advantages that GPT can't match. Knowing which is which is more useful than knowing the final score.
"Reading through the supplier recommendation, both provide identical short list and recommendation but I like the Opus way of presenting and details. This could go directly into a category manager report without much editing."
During RFP Analysis evaluationDual-mode, browser-based, no API shortcuts
We used a dual-mode testing design. Mode A: the exact same vendor-neutral prompt submitted to both models simultaneously. Tests out-of-the-box performance, what you get if you just paste a procurement task into either tool. Mode B: each model received a prompt engineered for its strengths. Opus got XML-tagged structure with self-verification instructions. GPT got outcome-first framing with explicit success criteria. Combined score = average of both modes.
Everything ran through the browser interfaces (claude.ai and chatgpt.com), not APIs. This was deliberate. AI for procurement teams means browser UIs, not API calls. File generation, follow-up behaviour, formatting choices: these are all part of the experience, and they only show up in the browser.
Opus could not be set to "High" compute in browser, only adaptive. GPT's thinking time varied from 3 minutes to 6 minutes depending on prompt style. These constraints mirror what your team actually experiences. API benchmarks don't capture this.
Four scoring dimensions per test: Accuracy/Completeness, Self-Consistency, Output Quality, and Instruction-Following. Each scored 0–10 for a maximum of 40 per mode, 80 per use case (two modes), 400 total across the evaluation. Full scoring rubric →
Final scores across 5 use cases
| Use Case | Opus 4.7 | GPT-5.5 | Delta | Winner |
|---|---|---|---|---|
| UC1: RFP Analysis & Evaluation | 38.0 | 34.5 | +3.5 | Opus |
| UC2: Contract Redlining | 36.25 | 34.75 | +1.5 | Opus |
| UC3: Spend Analysis & Savings | 36.5 | 36.5 | 0.0 | Tie |
| UC4: Category Strategy | 38.25 | 36.5 | +1.75 | Opus |
| UC5: Supplier Scorecard (QBR) | 37.5 | 36.25 | +1.25 | Opus |
| Grand Total | 186.5 /200 | 178.5 /200 | +8.0 | Opus |
Mode-level breakdown
GPT won exactly one mode across all 10 tests: Spend Analysis Mode A (with a clean, visually superior table layout). Opus won 8. One tie.
| Opus A | GPT A | A Winner | Opus B | GPT B | B Winner | |
|---|---|---|---|---|---|---|
| UC1: RFP | 37.0 | 34.0 | Opus | 39.0 | 35.0 | Opus |
| UC2: Contract | 36.0 | 33.5 | Opus | 36.5 | 36.0 | Opus |
| UC3: Spend | 35.5 | 36.5 | GPT | 37.5 | 36.5 | Opus |
| UC4: Strategy | 38.5 | 36.0 | Opus | 38.0 | 37.0 | Opus |
| UC5: QBR | 38.5 | 36.0 | Opus | 36.5 | 36.5 | Tie |
What Opus does better, and why it matters
The patterns that gave Opus its lead weren't random. They showed up repeatedly across use cases, and they map directly to things procurement professionals need from a working tool.
File generation: Opus produced downloadable files in 5 of 10 tests (.docx, .md). GPT produced zero. For a category strategy that needs steering committee approval, a formatted .docx with title page and signature lines is immediately usable. Browser output needs reformatting.
Self-verification: Opus catches its own errors before presenting output. In the Supplier Scorecard test, it applied set theory (inclusion-exclusion principle) to verify OTIF data. In RFP Analysis, it documented three specific score revisions. GPT's checks were declarative: "I checked" without showing what changed.
Separation of prompted vs. additional analysis: Opus explicitly labels "what you asked for" separately from "what I'm flagging in addition." GPT delivers everything in one stream. When you need to know what's in-scope vs. bonus insight, that separation matters.
Advisory tone: Opus tells you what to DO about each finding. GPT describes what's wrong. One gives you homework; the other gives you an action plan.
Speed: Opus was consistently faster across all five use cases. GPT's thinking time ranged from 3 to 6 minutes; Opus completed while GPT was still processing.
If you read our Opus 4.7 review, some of these will sound familiar. The self-verification and advisory tone were exactly the behaviours that set 4.7 apart from 4.6. They hold up against external competition too.
What GPT does better (and it's not nothing)
GPT-5.5 has real strengths that showed up clearly in the evaluation. Ignoring them would make this article less useful to you.
External citations: GPT consistently sourced external references. In Category Strategy Mode B, it peaked at 16 citations: EUDR and PPWR regulatory timelines, named supplier profiles (WPP, Publicis, Omnicom, Dentsu, Havas), WARC data, IAB Europe statistics. Opus never cited an external source in any test.
Research depth: In Spend Analysis, GPT cited NLW rates, BCIS construction forecasts, and ONS indices to benchmark savings assumptions. This is evidence that would take a procurement analyst hours to assemble manually.
Format quality in specific tests: GPT's Kraljic segmentation table in Spend Analysis Mode A was cleaner and more visually accessible. Its tables had a polish that Opus didn't match in that particular test.
Mode B improvement curve: GPT responded more dramatically to prompt optimisation. In Contract Redlining, it went from long prose blocks (Mode A) to a clean 4-column table format with a "Dear Nexus team" supplier letter (Mode B), the single biggest format improvement of any model in any test.
"Overall formatting GPT wins for sure. I think Opus has some practical data insights but GPT also gathered good information to support."
During Spend Analysis Mode A evaluationThe citation advantage deserves emphasis. When you're building a business case for a sourcing initiative and need to cite market data, regulatory timelines, and industry benchmarks, GPT gives you something Opus currently doesn't. It introduces a verification burden (are those citations current? are the links live?), but the raw research depth is real.
What actually happened in each test
Scores tell you who won. The stories below tell you why, and which moments would matter in your own workflows.
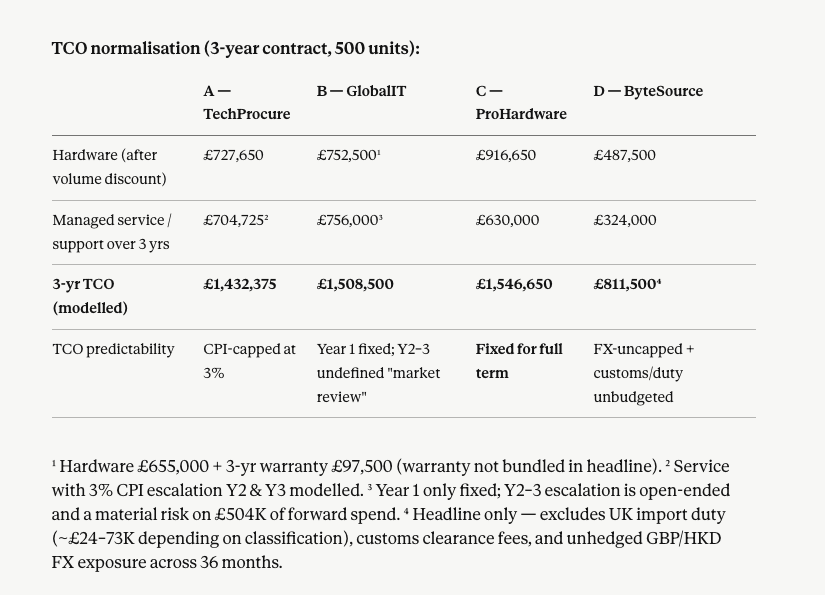
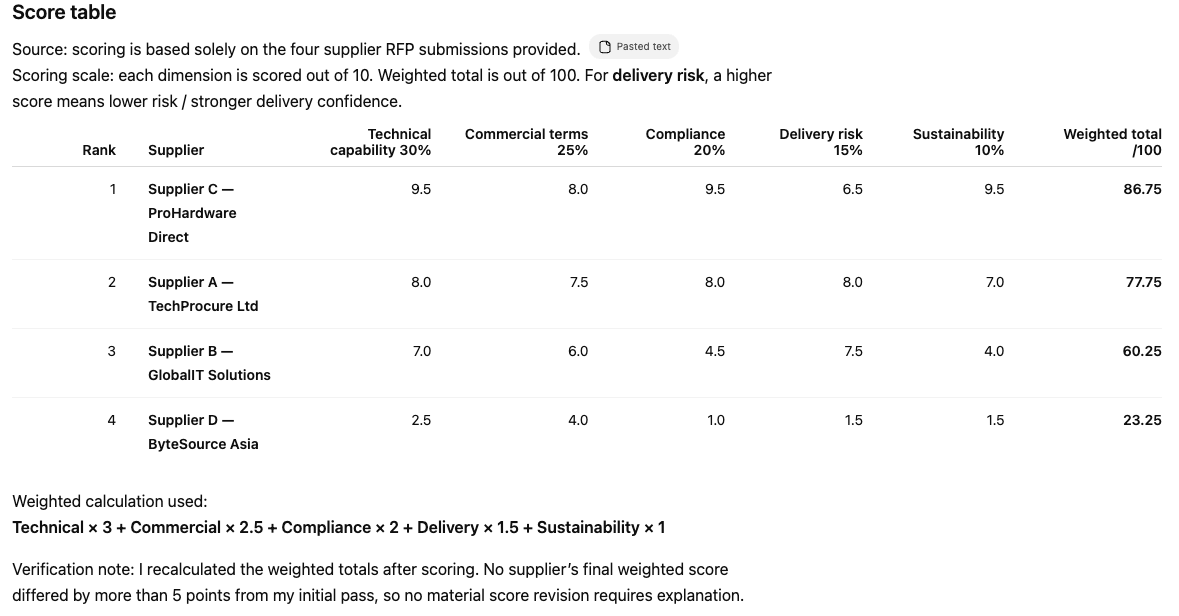
Four supplier responses for a 500-unit enterprise laptop procurement (£2.5M ceiling, 3-year managed service). Both models ranked the suppliers identically: ProHardware 1st, TechProcure 2nd, GlobalIT 3rd, ByteSource 4th. Same conclusion from different analytical paths, which gave us confidence in the synthetic data.
The ByteSource disqualification note. Before even showing scores, Opus flagged that ByteSource would "normally be removed at the disqualification stage" due to spec non-compliance. That's procurement domain judgement: knowing that a supplier who can't meet the basic spec shouldn't be in the scoring grid at all. GPT scored ByteSource without comment.
The TCO table nobody asked for. The prompt didn't request a separate TCO analysis. Opus built one anyway: a full normalisation table with footnoted assumptions. It inferred that a proper commercial evaluation of four IT suppliers requires lifecycle cost comparison, not just headline pricing. This echoes a pattern we observed in Issue #1: Opus adds unrequested analytical depth when it judges the task requires it.
GPT's 6-minute thinking time. In Mode B, GPT thought for almost 6 minutes (vs 3 in Mode A). The outcome-first prompt doubled its reasoning effort and produced measurably better output. Concrete evidence that prompt style affects how hard the model works.
Recommendation quality: Opus's recommendation read like a category manager wrote it: three specific pre-award conditions for ProHardware, negotiation points, next steps. GPT gave a correct shortlist but didn't tell you what to do next.
This result tracks with what we found in our dedicated RFP comparison last week. Claude scored 85.1 to GPT's 66.9 on a minimal-prompting enterprise CRM RFP. The full evaluation here confirms the pattern: Opus treats RFP evaluation as a procurement advisory task, not just a scoring exercise.
A 12-clause supplier services agreement (£800,000 p.a., 3-year term) with embedded deviations from standard terms and internal inconsistencies. Both models found the same high-risk issues. The scoring came down to what they did with them.
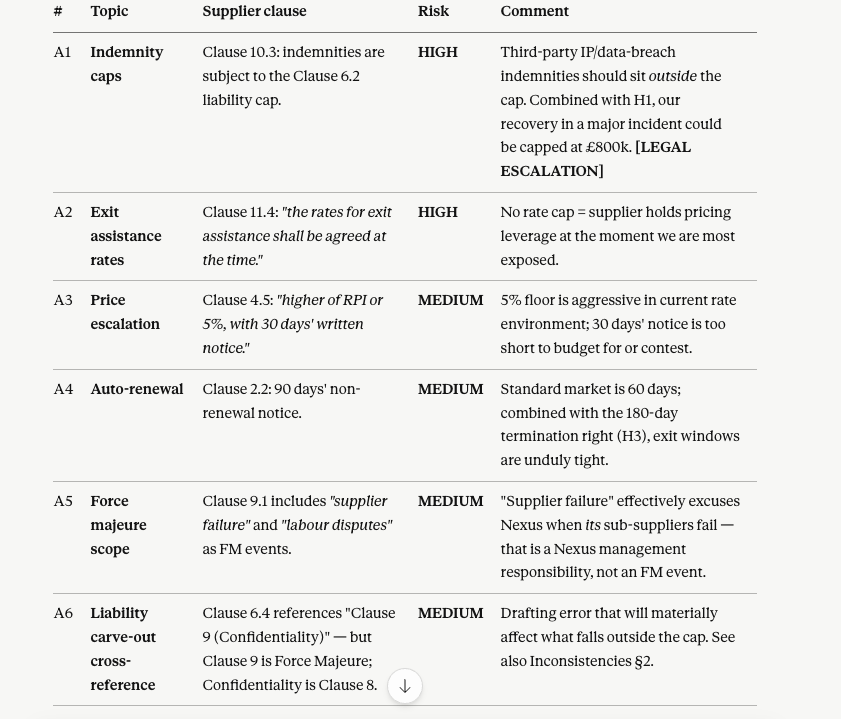
The Clause 6.4/9 cross-reference error. Opus found that Clause 6.4 carves out "Clause 9 (Confidentiality)" from the liability cap, but Confidentiality is actually Clause 8. Clause 9 is Force Majeure. As drafted, Force Majeure events could be excluded from the liability cap entirely. A real drafting defect with material legal consequence.
The £800k vs £800,004 catch. Clause 1.2 defines the contract value as "£800,000 per annum." Schedule 2 states "£800,004/year" (12 × £66,667). Minor, but important because the liability cap is calculated as a percentage of contract value. Which number applies?
The "Dear Nexus team" format swap. In Mode B, GPT made the biggest single format improvement of the entire evaluation. It went from long prose blocks to a clean 4-column table with a ready-to-send supplier letter: "Dear Nexus team, We have reviewed the draft IT Managed Services Agreement against Hartwell Retail Group plc's standard contracting positions..." Meanwhile, Opus moved in the opposite direction: fewer tables, more narrative executive-report style.
Verbatim revision quality: Opus's suggested revision for Price Escalation specified the index (CPI), source (ONS), cap mechanism (lower of CPI or 3%), grace period, and dispute trigger. That could go directly into a counter-draft.

A 12-month Facilities Management spend dataset (20 line items, 19 suppliers, 11 sub-categories, 47 UK sites) with a deliberate £200k arithmetic error: the stated total didn't match the sum of the rows. Both models caught it. How they handled the rest diverged sharply.
The £414k combined data gap. Opus didn't just flag the £200k variance. It combined it with the £214k "Misc/Unknown" bucket to compute a total data integrity gap of £414k (3.3% of category spend). Cumulative thinking that GPT didn't show.
Veolia "7 weeks away." Opus anchored its analysis to real-time deadlines, flagging Veolia's contract expiry as "June 2026 (~7 weeks away)" and recommending "Launch renewal RFP this month." This turns a spend analysis into an action plan. GPT noted the expiry without the temporal urgency.
GPT's only Mode A win. GPT took Spend Analysis Mode A, its only Mode A win across all five use cases. The tables were cleaner, the Kraljic segmentation more visually accessible, and the external citations (NLW rates, BCIS forecasts, ONS indices) added evidence-backed context for savings assumptions.
Savings ranges: GPT: £0.56M–£1.67M. Opus: £550K–£1.4M. Close enough to suggest both are drawing from the same FM consolidation benchmarks. Opus explicitly caveated: "That range explicitly assumes static labour rates. Given NLW increases, gross savings will be partially offset." GPT cited the NLW data but didn't flag the dependency as explicitly.

Build a 12-month marketing category strategy for a European retail chain: €20M spend, 5 markets, 12 product launches, 40+ fragmented agencies. Complex enough that analytical quality shows clearly.
File generation as competitive moat. Opus produced a 14-page .docx: title page, executive summary, Kraljic mapping, sourcing roadmap, KPIs with named data sources, contingency plan, signature lines. Stakeholder-ready. GPT produced detailed browser output with 16 citations, but no file. For a document that needs steering committee sign-off, the .docx wins.
GPT's 16 citations. This was GPT's strongest output of the entire evaluation. EUDR and PPWR regulatory timelines with effective dates. Named supplier profiles (WPP, Publicis, Omnicom/IPG, Dentsu, Havas, HH Global). WARC global ad spend data. IAB Europe programmatic share statistics. A procurement director could use those supplier profiles directly in market engagement. That's research quality that would take hours to assemble manually.
The savings confidence caveat. Opus explicitly flagged: "The savings figures are industry-benchmark ranges applied to your stated €20M spend. They're directionally right for sizing the prize, but the real numbers come out of the Q1 2026 fee benchmarking." That kind of intellectual honesty about the limits of its own analysis builds trust with a CFO audience.
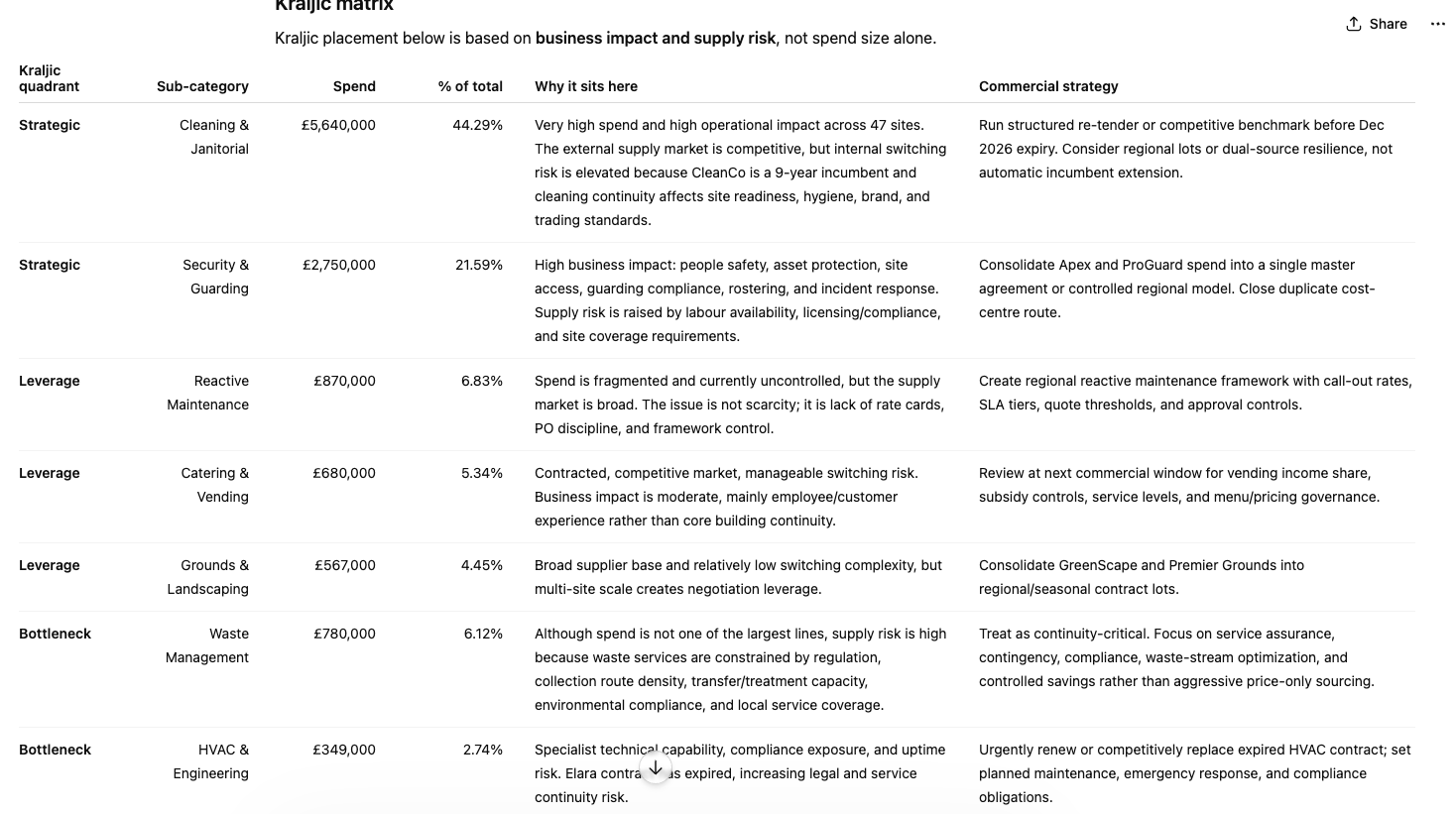
Strategic option evaluation: Both reached the same conclusion (tiered preferred supplier panel). Opus explicitly showed its reasoning for rejecting the other three options: single source, full outsource, in-house agency. This "show your working" approach is more useful for a procurement director who needs to defend the recommendation.

A full-year QBR pack for a food packaging supplier: quarterly OTIF figures, quality incidents across severity levels, commercial metrics, non-conformance reports with root cause analysis. The most data-intensive test.
The inclusion-exclusion catch. Before producing any analysis, Opus identified a mathematical impossibility in the OTIF data: "For Q1: 128 on-time + 134 in-full out of 142 orders. By inclusion-exclusion, the minimum possible OTIF count is 128 + 134 − 142 = 120, but the data says 116. That's mathematically impossible unless some orders were neither on-time nor in-full..." It applied set theory to verify the source data before running calculations. GPT did not catch this.
Quality scoring methodology divergence. Opus used a continuous deduction model (start at 10, subtract weighted penalties per incident). GPT used a banded severity index lookup. The practical impact: Opus scored Q1 quality at 0.10/10; GPT scored it at 2.0/10. Both are defensible methodologies, but the divergence shows how much the approach matters when the output is going to a supplier in a formal review.
The copy-paste catch. During the evaluation, when GPT's Mode B response was pasted for documentation, Claude (acting as evaluation co-pilot) immediately flagged: "Wait, this is identical to Opus Mode B. Every number, every sentence..." A data integrity incident caught in real-time, before it could contaminate scoring. This is why evaluation methodology matters.
GPT's NC-003 timing catch: GPT spotted that NC-003's production date (14/03/2025) falls in Q1 despite being reported in Q2. Opus missed this. A solid data quality observation from GPT.
Mode B changed both models, but differently
Quick refresher: Mode A gave both models the exact same vendor-neutral prompt: no hints, no structure, just the task. Mode B gave each model a prompt engineered for its strengths: Opus got XML-tagged structure with self-verification instructions; GPT got outcome-first framing with explicit success criteria. Mode B tests what happens when you learn how the model works and write prompts accordingly.
Both models improved with optimised prompts. But the nature of the improvement diverged. GPT's biggest gains were in format and presentation: tables appeared where prose had been, supplier letters materialised, visual layout sharpened. Opus's biggest gains were in verification depth: dedicated self-check sections, calculation reconciliation tables, explicit confidence levels.
The format convergence in Contract Redlining was the most interesting finding. GPT adopted tables (Opus's natural Mode A strength). Opus adopted narrative executive-report style (closer to GPT's natural register). The models literally swapped approaches in Mode B. Prompt engineering didn't just improve output. It changed the fundamental shape of the response.
In RFP Analysis, Opus's unrequested TCO table disappeared in Mode B because the XML format spec didn't include it. The structured prompt produced better self-verification but suppressed creative analytical additions. Structure vs. creative latitude is a real trade-off, and you'll hit it when you write prompts for either model. This is one reason procurement AI projects fail: teams skip the prompt engineering work.
We're publishing a companion article on the prompt engineering experiment in detail: what specifically changed, what each prompt structure triggered, and what you can steal for your own workflows. That article will cover the specific XML tags that triggered Opus's verification behaviour, and the outcome-first framing that doubled GPT's thinking time.
What should your team actually do with this?
If you're a CPO or procurement leader deciding which AI tools to standardise across your function, here's how we'd deploy these models for procurement teams based on the evaluation results.
"For the areas where Opus went further, it presented them separately (additional clauses worth flagging) so it's trying to tell us what the extra work is vs what you actually asked for. I find that useful."
During Contract Redlining evaluationOpus 4.7 vs GPT-5.5 at a glance
| Dimension | Opus 4.7 | GPT-5.5 |
|---|---|---|
| File generation | 5/10 tests .docx, .md files from browser | 0/10 tests Browser output only |
| Self-verification | active Shows revisions, catches arithmetic | declarative States "I checked" without evidence |
| External citations | none Never cited external sources | strong Up to 16 citations with live links |
| Speed | faster Consistently across all 5 UCs | slower 3–6 min thinking time |
| Advisory tone | actionable Tells you what to do about findings | descriptive Tells you what's wrong |
| Format quality | Strong tables in Mode A; narrative in Mode B | Cleaner tables in specific tests (Spend Analysis) |
| Domain depth | Applied judgement (disqualification flags, temporal awareness) | Research breadth (market data, regulations, benchmarks) |
| Prompt responsiveness | Structure triggers verification; can suppress creativity | Dramatic format improvement with optimised prompts |
What does each model actually cost to run?
Both models sit at premium pricing tiers. These are flagship products. Here's what the official rate cards say:
Source: Anthropic Pricing → · OpenAI Pricing →
Input pricing is identical at $5/MTok. The difference is output: Opus costs $25/MTok vs GPT's $30/MTok, a 20% premium on GPT output tokens. For procurement workflows that produce long outputs (category strategies, contract reviews, QBR packs), that gap adds up.
There are two real-world caveats that complicate the headline numbers:
Opus's new tokenizer: Opus 4.7 ships with an updated tokenizer that can produce up to 35% more tokens for the same input text compared to 4.6. The rate card didn't change, but your effective cost per request may have gone up.
GPT's long-context surcharge: Prompts exceeding 272K tokens trigger 2x input and 1.5x output pricing for the full session. If you're feeding GPT-5.5 large contract bundles or full spend datasets, the 1M context window comes at a steep multiplier.
GPT's thinking time: In our browser testing, GPT-5.5 spent 3–6 minutes thinking per response. That extended reasoning burns output tokens internally. Opus was consistently faster, which likely translates to fewer total tokens consumed per task.
For teams using the API with prompt caching (Anthropic offers up to 90% off cached input; OpenAI offers 50% batch discount), the economics shift further. But for browser-based usage (which is how most procurement teams interact with these models), the subscription pricing ($20/month for ChatGPT Plus, $20/month for Claude Pro) makes the per-token calculus irrelevant. At the subscription level, you're paying for usage limits and model access, not individual tokens.
Bottom line: if you're running these through the API at scale, Opus is 20% cheaper on output and likely faster (fewer total tokens per task). If you're on browser subscriptions, the cost difference is negligible. Pick the model that produces better outputs for your use case and you'll save more on team time than you'll ever save on tokens.
Our verdict: You won't go wrong with either
Let's be direct: both these LLMs are excellent at procurement work. The lowest score in this entire evaluation was 83.75%. Neither model produced anything you'd be embarrassed to put in front of a stakeholder. If your team is already using one of these, there's no urgent reason to switch.
Both models feel like overkill for most daily procurement tasks. These are flagship, high-intelligence models loaded with capabilities that most routine procurement workflows don't need. A supplier email summary, a basic spend pivot, a first-pass contract review. You don't need a model that can apply set theory to OTIF data or cite 16 regulatory sources for that.
For most teams, our practical recommendation: use Claude Opus 4.6 and GPT-5.4 as your daily workhorses. They're faster, cheaper, and more than capable for the 80% of procurement tasks that are well-scoped and routine. Save the flagship models (Opus 4.7 and GPT-5.5) for the specialised work that actually demands their intelligence: heavy spend analysis across thousands of line items, reviewing dozens of contracts in one session to find a specific pattern, deep market research for annual category strategies, or building a business case that needs cited evidence to survive a CFO challenge.
When you do reach for the flagships, Opus 4.7 edges it for procurement-specific work: file generation, self-verification, advisory tone, and speed. In Issue #1, we said Opus 4.7 felt like a real domain expert. Since then we've used it extensively in real client workflows and ran this comparative test three times, and we stand by that statement. Opus 4.7 demonstrates expert-level domain knowledge across multiple procurement categories: it knows when to disqualify a supplier, how to structure a Kraljic matrix, when a liability cap calculation matters, and how to frame a recommendation a CPO would actually present. That kind of contextual intelligence makes it the best AI for procurement teams working across multiple categories simultaneously.
GPT-5.5 wins when you need external research depth baked directly into the output. Both improve significantly with prompt engineering (Mode B improved both by measurable margins), so invest the time regardless of which you choose.
A note on "drawbacks": most of the weaknesses we flagged in this evaluation are easily prompted out once you understand how each model behaves. GPT doesn't produce downloadable files by default, but add one line to your prompt ("export as .docx") and the issue is gone. Opus doesn't cite external sources, but add "cite relevant market data and regulations with sources" and it will. GPT's Mode A formatting was verbose. A sentence of structure instruction fixed it in Mode B. These aren't hard limitations. They're defaults that shift with a well-written prompt. The real question is which model's defaults are closest to what you need out of the box, and that's where Opus has the edge. For any CPO choosing between ChatGPT for procurement workflows and Claude, the defaults matter more than the ceiling.
For a closer look at how these models compare specifically on RFP generation with minimal prompting, see our quick-fire RFP comparison: Claude 85.1, GPT 66.9, consistent with what we found here.
If you're evaluating which AI tools to deploy across your procurement function, that's exactly what we work through with clients. Our AI procurement consulting team helps you choose the right models, build the workflows, and measure ROI. For teams that need hands-on capability building, our AI training for procurement teams covers prompt engineering, tool selection, and adoption strategies.
Not sure where to start? Take our AI Readiness Assessment, read our step-by-step guide to implementing AI in procurement, or explore 12 AI use cases in procurement that actually work.
Approach
Five self-contained procurement scenarios were developed using synthetic data (fictional suppliers, spend figures, contract terms). Each was tested in two modes: Mode A (identical vendor-neutral prompt to both models) and Mode B (prompt engineered for each model's strengths). All testing was conducted via browser interfaces (claude.ai and chatgpt.com), not APIs, to reflect actual procurement team usage patterns.
Mode A prompts were submitted simultaneously. Mode B prompts: Opus received XML-tagged structure with <role>, <data>, <task>, <output_format> tags plus self-verification instructions. GPT received outcome-first framing with explicit success criteria and benchmarks.
Combined UC Score = (Mode A + Mode B) / 2. This captures both out-of-the-box performance and peak performance under optimal prompting.
Scoring Dimensions
| Dimension | What was assessed | Max |
|---|---|---|
| Accuracy / Completeness | Coverage of all required elements; correct facts, calculations, and references; detection of embedded data traps; external evidence quality | 10 |
| Self-consistency | Internal agreement between numbers, scores, and narrative; evidence of self-check execution; no contradictions between sections | 10 |
| Output quality | Usability without further editing; actionability for the intended audience; file generation; visual formatting; supplier-readiness | 10 |
| Instruction-following | All numbered steps completed; format requirements met; no required elements missed; appropriate scope management | 10 |
Test Environment
Browser-based: claude.ai (Opus 4.7, adaptive compute; "High" setting not available in browser) and chatgpt.com (GPT-5.5). No API access was used.
Simultaneous submission: Mode A prompts submitted to both models at approximately the same time to control for any time-sensitive factors.
Evaluator: Sandeep Karangula (Molecule One), with Claude (Cowork mode) acting as evaluation co-pilot: documenting responses, facilitating scoring, and flagging discrepancies in real time.
Caveats
Single-run results: Each use case was run once per model per mode. LLM outputs have inherent variability. The patterns were consistent enough across five use cases (10 total tests) to draw conclusions, but individual scores are directional.
Compute constraint: Opus could only run in adaptive mode (not "High") in the browser. This means Mode B tests the prompt structure difference only, not the effort setting. If Opus on High produces better output than adaptive, the gap would widen.
Synthetic data: All supplier names, spend figures, contract terms, and performance data are fictional. Results reflect model behaviour on these scenarios.
Evaluator bias: The evaluation was conducted by a single assessor. Subjective dimensions (particularly Output Quality) reflect one professional's preferences. The format preferences noted in the article (e.g., Opus's table layout being preferred in Contract Redlining) are acknowledged as potentially personal.
No token counting: Browser-based testing means no API-level token measurement. Speed observations are qualitative wall-clock assessments.
GPT-5.5 vs Claude Opus 4.7 for procurement: FAQ
Is GPT-5.5 or Claude Opus 4.7 better for procurement work?
Claude Opus 4.7 scored 186.5 to GPT-5.5's 178.5 across five procurement use cases. Opus won four of five (RFP scoring, contract redlining, category strategy, supplier QBRs) with one tie in spend analysis. Opus has the edge in file generation, self-verification, advisory tone, and speed. GPT-5.5 wins on external citations and research depth. For most procurement workflows, Opus is the stronger default.
Can GPT-5.5 generate downloadable procurement documents?
Not from the browser by default. In our testing, GPT-5.5 produced zero downloadable files across 10 tests. Claude Opus 4.7 generated .docx and .md files in 5 of 10 tests, including a 14-page category strategy with signature lines. Adding "export as .docx" to your GPT prompt can address this, but Opus does it unprompted.
Which AI model is best for RFP evaluation?
Claude Opus 4.7 scored 38.0 vs GPT-5.5's 34.5 on RFP analysis. Opus flagged a supplier for disqualification before scoring, built an unrequested TCO normalisation table, and wrote recommendations with specific pre-award conditions. GPT ranked suppliers correctly but provided less actionable next steps. See our detailed RFP comparison for a minimal-prompting test.
How much does it cost to use GPT-5.5 vs Claude Opus 4.7?
Input pricing is identical at $5/MTok. Output costs differ: Opus at $25/MTok vs GPT-5.5 at $30/MTok (20% more for GPT). Browser subscriptions are both $20/month. Opus was consistently faster in our tests, meaning fewer tokens consumed per task. For API usage at scale, Opus is the cheaper option.
Should procurement teams use both models?
If budget allows, yes. Use Opus for stakeholder-ready documents, contract review, and RFP scoring. Use GPT-5.5 when you need cited market data, regulatory timelines, and industry benchmarks for business cases. For routine daily tasks, lighter models (Claude Opus 4.6, GPT-5.4) are faster and cheaper. Our AI procurement consulting team helps organisations build this kind of multi-model workflow.
Molecule One builds AI-native procurement tools for mid-market and enterprise buyers. We help procurement teams deploy and get measurable value from AI in the workflows you run every day, not just in theory.
← Issue #001: Claude Opus 4.7 Review
Issue #002 · May 2026 · sk@moleculeone.ai · moleculeone.ai