AI RFP Drafting Put to the Test: We Gave GPT-5.5 and Claude Opus 4.7 the Same Enterprise Brief. The Scores Should Worry Every Sourcing Leader
OpenAI and Anthropic both shipped new flagship models this quarter. We tested them head-to-head on a real procurement workflow to see which one actually performs in production.
Claude Opus 4.7 wins 85.1 to 66.9. But read the detail.
OpenAI released GPT-5.5. Anthropic shipped Claude Opus 4.7. Both are the flagship models from the two companies leading the AI race right now. We wanted to know how they perform when you hand them a real procurement workflow. So we gave both models the same enterprise RFP brief that a senior category manager would normally spend two weeks on.
So we gave both models the same task: "Draft a full enterprise RFP for a multi-country CRM modernisation program across 14 markets, including vendor qualification criteria, technical architecture expectations, implementation governance, commercial evaluation, SLAs, risk controls, legal terms, and weighted scoring."
That prompt is deliberately thin. It fails most prompting best practices: no role assignment, no example output, no constraints on format or length. We did that on purpose. These are the highest-intelligence models both companies offer. We wanted to see how far each one could go with minimal guidance, how much programme context each model would infer on its own, and where each one would default to placeholders instead of making a call.
Both came back in under a minute. Both had the right section headings, the right vocabulary, the right shape on the page. RFP drafting is one of the most requested AI use cases in procurement, so the speed alone was striking.
Then we sat down to actually evaluate both outputs, section by section, criterion by criterion. The scoring difference between the two models was wider than expected. Wide enough that one of them would fall apart the moment a vendor's bid team started reading it.
"GPT-5.5 describes the category of obligation. Claude Opus 4.7 specifies the actual obligation."
Head-to-head verdict
We built a comparison tool that scores both drafts across nine weighted dimensions: technical architecture (15 pts), commercial evaluation (13 pts), governance (12 pts), the rest ten each. Weights chosen to reflect what actually matters in a CRM modernisation tender.
GPT-5.5 was the generalist: polished, well-structured, every section the prompt asked for. Claude Opus 4.7 behaved like a model that understood what the brief actually required, producing output that read like someone who had run a global CRM rollout had written it.
We saw the same pattern in our full Handshake review of Claude Opus 4.7 when it first launched. In that test, the model went deep into marketing category management and related sustainability topics with the fluency of a domain expert. It is consistent: Opus 4.7 behaves like a model with genuine procurement domain knowledge, and that showed up again here across commercial structure, legal terms, and multi-country specificity.
The interesting thing is where the two models diverged.
Nine dimensions, scored 0-10
| Dimension | Weight | GPT-5.5 | Opus 4.7 | Winner |
|---|---|---|---|---|
| Vendor Qualification | 10 | 6 | 9 | Opus 4.7 |
| Technical Architecture | 15 | 7 | 9 | Opus 4.7 |
| Implementation Governance | 12 | 8 | 8 | Tie |
| Commercial Evaluation | 13 | 6 | 10 | Opus 4.7 |
| SLAs & Performance | 10 | 6 | 9 | Opus 4.7 |
| Risk Controls | 10 | 7 | 7 | Tie |
| Legal Terms | 10 | 6 | 9 | Opus 4.7 |
| Scoring Methodology | 10 | 8 | 6 | GPT-5.5 |
| Multi-Country Coverage | 10 | 6 | 9 | Opus 4.7 |
| Weighted Total | 100 | 66.9 | 85.1 | Opus 4.7 |
Vendor qualification: binary versus aspirational
GPT-5.5 listed ten qualification categories, three comparable implementations, five-country delivery history. The usual list. Sensible on paper. But every threshold was generic, none enforced as a pass/fail gate, no insurance minimums, no required evidence format.
Claude Opus 4.7 built a binary mandatory screen: ten items, each auditable, each disqualifying if missed. ISO/IEC 27001:2022. SOC 2 Type II within twelve months. USD 25M PI insurance, USD 50M cyber liability. Named in-region processing entities per regulated jurisdiction. A vendor authorisation letter from the platform vendor. Three case studies with measurable outcomes and facilitated reference contacts. Sanctions screening. Three years of audited financials.
That is the difference between a qualification stage that filters and one that performs filtering theatre.
Technical architecture: where the scores diverge
GPT-5.5 had a respectable ten-principle architecture framework, a component list, an integration catalogue by system type, and an NFR table covering 99.9% availability and WCAG 2.1 AA. Thorough on the surface. But it did not name a single specific system, did not address data tenancy market by market, did not reference any specific regulatory regime, and, crucially in 2026, had no AI or GenAI governance requirements. None.
Claude Opus 4.7 named all eighteen integration systems: SAP S/4HANA, Genesys Cloud, Adobe AEP, Marketo, Workday, ServiceNow, the full list. It mandated a data residency table covering nine regulatory regimes (GDPR, UK GDPR, FADP, CCPA/CPRA, LGPD, PIPL, PDPA, UAE PDPL, APPI) with cross-border transfer mechanisms specified. It included a dedicated AI/GenAI section requiring EU AI Act compliance, tenant data isolation, model card transparency, and a written commitment that prompt and output data would not be used to train third-party models. 99.95% availability. Bring-your-own-key encryption.
The writing quality was comparable. What separated them was whether the document encoded the actual programme or just described the abstract shape of one.
Governance: a surprising tie
Both defined named forums with frequency and participants. Both listed key personnel roles. GPT-5.5 had slightly better appendices: a more detailed workstream structure, more explicit example stage gates, stronger change management KPIs. Claude Opus 4.7 added an Architecture Review Board and a Quarterly Business Review, plus a contractually committed key-personnel clause with thirty-day like-for-like replacement at supplier cost. That matters more than it sounds. Key-person risk on a programme this size is real and most RFPs handle it with hand-waving.
Commercial evaluation: the largest scoring difference
6 versus 10, the widest scoring difference of any dimension. GPT-5.5 had a five-year TCO framework, a rate card, an outcome-based milestone table. Reasonable bones. But it did not name actual volumes, did not lock down a pricing submission format, did not specify currency, uplift caps, payment terms, liability caps, IP ownership, or benchmarking rights. It asked vendors to submit pricing without telling them what to price against, in what format, in what currency, or under what commercial terms. Any procurement professional reading that knows exactly how it ends: twelve different pricing structures, none comparable, all defensible by the bidding vendor.
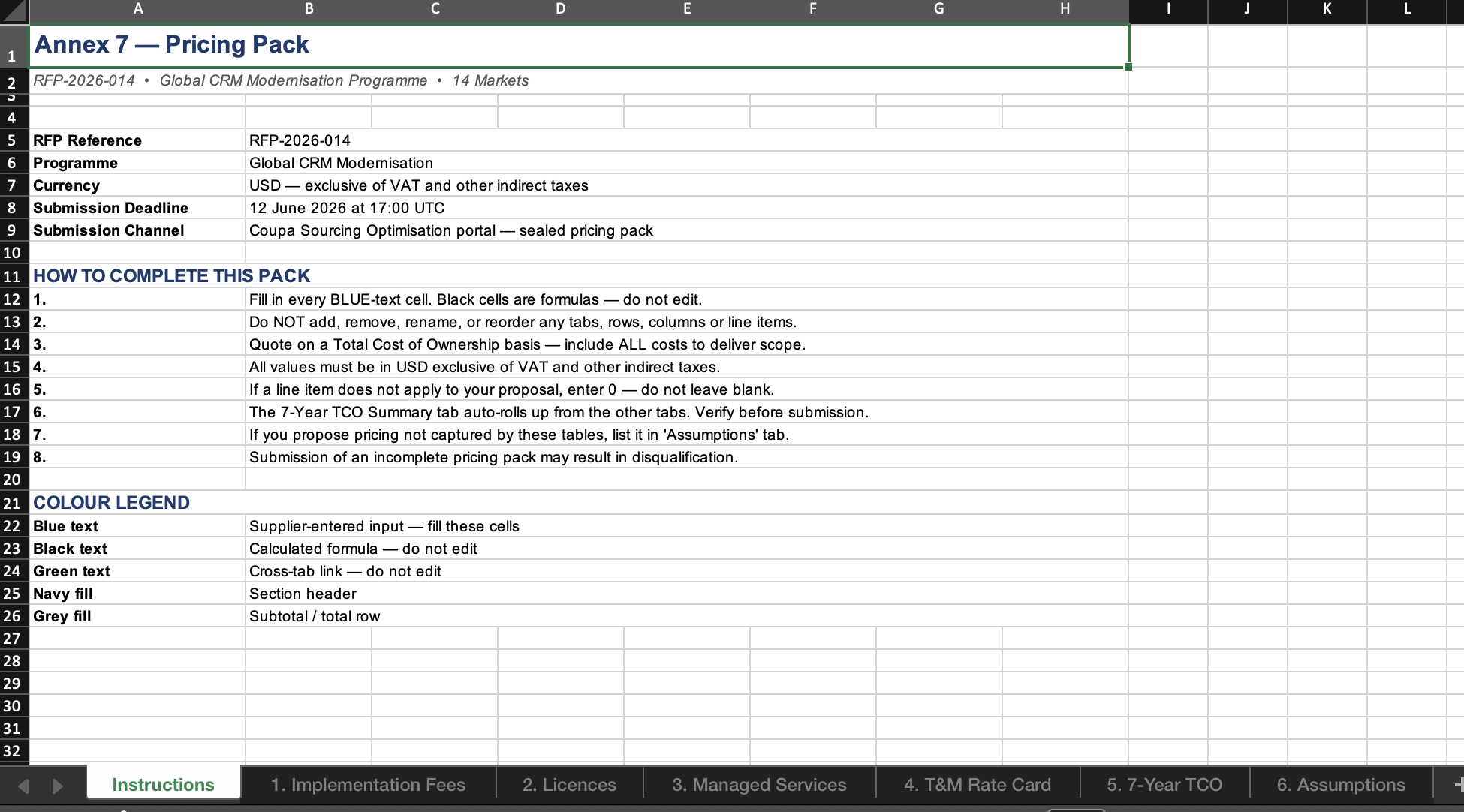
Claude Opus 4.7 came with a paired Excel pricing pack: a structured, formula-protected, seven-year TCO model. Fixed-price implementation deliverables tied to actual scope (47 million records, 18 named integrations, 9,500 users, 11 languages). Per-user-per-month licence tables. A T&M rate card with onshore, nearshore, and offshore day rates and uplift caps. A sealed submission channel via Coupa. And the part we genuinely respected: a commercial terms table that committed vendors to specific positions. Net 60 payment terms, FX risk corridors, liability caps (USD 50M direct loss, USD 100M data breach), MFN benchmarking in Years 4 and 6, IP ownership of bespoke work product, twelve-month exit assistance.
One document produces evaluable bids. The other produces an evaluation nightmare.
SLAs and legal terms: same pattern
GPT-5.5 listed categories and asked vendors to flag exceptions. Claude Opus 4.7 stated positions: 99.95% availability with tiered service credits, P1 response at 15 minutes, RPO of 4 hours and RTO of 8 hours, security incident notification within 24 hours, critical patches within 14 days of CVE publication. On legal: governing law as England and Wales with LCIA arbitration, specific liability caps, IP ownership of bespoke work product, termination notice periods, audit rights, MFN benchmarking, and twelve months of exit assistance. GPT-5.5's output reads like a topic list. Claude's reads like a negotiating baseline.
Scoring methodology: where GPT-5.5 won
This one is worth dwelling on. GPT-5.5 published a fully transparent ten-category weighted scoring model with explicit percentages, a 0-5 scale, definitions for each level, and the formula. A vendor knows exactly how their proposal will be evaluated.
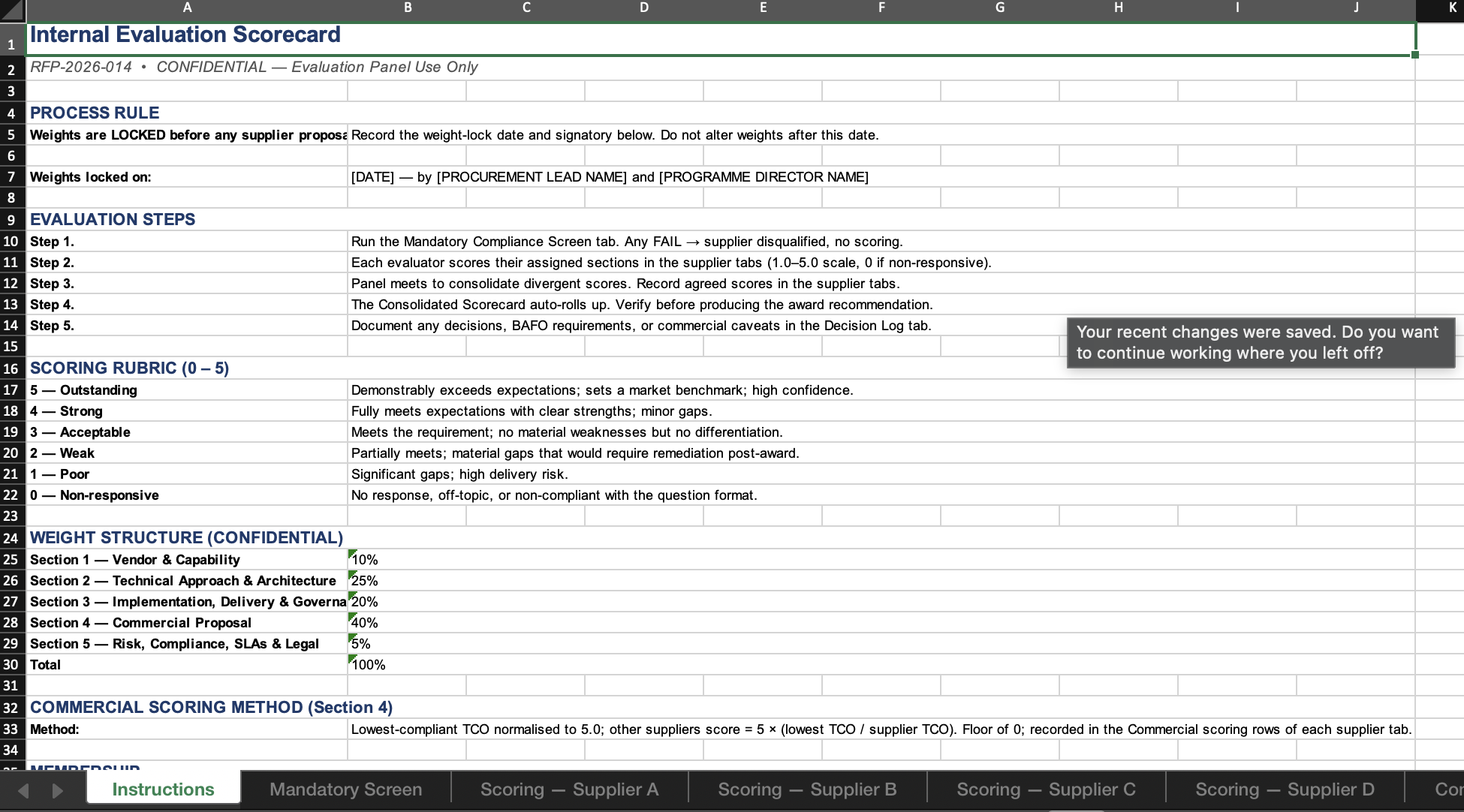
Claude Opus 4.7 deliberately withheld specific weights as confidential to the panel, disclosing only indicative section weights. The reasoning is sound: it reduces gaming and protects evaluator independence. But it also reduces vendor transparency.
We are honestly torn on which is right. GPT-5.5's transparency wins on procurement orthodoxy. Claude Opus 4.7's opacity wins on protecting the panel's judgment. Probably depends on whether you trust your vendor pool to engage in good faith.
Multi-country coverage: the widest scoring difference
GPT-5.5 talked about 14 markets but listed all of them as placeholders. No user counts, no languages, no wave assignments, no regulatory regimes. Claude Opus 4.7 provided a complete per-market breakdown: sales, service, marketing, and partner users for all 14 named markets (US, Canada, UK, Germany, France, Italy, Spain, Netherlands, UAE, Japan, Singapore, Australia, Brazil, Mexico), with eleven local languages, wave assignments, per-jurisdiction data residency, the parallel SAP S/4HANA dependency, and the data residency constraints for EU/EEA, UK, Switzerland, Brazil, and mainland China.
This is the dimension where the difference between "looks like an enterprise RFP" and "is an enterprise RFP" becomes most visible.
Where each draft falls short
- 01All 14 markets are placeholders with no user counts, languages, wave assignments, or regulatory regimes, making vendor pricing and planning impossible
- 02No concrete commercial terms: no liability cap quantum, no governing law, no dispute forum, no IP ownership formulation, no insurance minimums
- 03No AI/GenAI governance requirements: no tenant data isolation, EU AI Act compliance, or model training prohibitions
- 04No mandatory qualification gate: criteria are aspirational minimums with no binary pass/fail enforcement
- 01Evaluation weights and rubrics confidential to the panel, reducing vendor transparency and ability to differentiate
- 02No exhaustive functional requirements matrix. The capability-by-capability response template present in GPT-5.5 is absent
- 03Missing benefits and KPI appendix. No equivalent to GPT-5.5's adoption, data quality, and compliance KPI framework
- 04Annex 2 (Integration Inventory) truncated, leaving the full 18-system integration detail incomplete
What this comparison tells us about both models
Claude Opus 4.7 is the stronger model for production procurement workflows right now. It treated the brief as a real programme, inferred programme-specific detail from the context we provided, and refused to leave critical commercial and legal positions as placeholders. GPT-5.5 filled the structure competently and moved on. That difference shows up across every dimension where specificity matters: commercials, legal, multi-country coverage, vendor qualification. These are the dimensions where weak RFPs fail in practice. This is one of the core procurement AI mistakes we see teams making: assuming that a polished-looking output is a usable output.
That said, GPT-5.5 is not a bad model. It produced a genuinely useful structural foundation, its scoring methodology was more transparent, and its functional matrix and KPI appendix were stronger than anything Claude produced. In a workflow where you are starting from a blank page, GPT-5.5 gives you a clean skeleton to build on. The problem is that a skeleton is not what you issue to vendors.
"Claude Opus 4.7 pulled harder on the brief, inferred programme detail, and committed to positions. GPT-5.5 filled the template and moved on. That is the production workflow difference."
Both models are capable of producing all the language in either draft. The difference was how each model handled context. Claude Opus 4.7 asked sharper implicit questions about the programme and generated answers from what we gave it. GPT-5.5 defaulted to safe placeholders. That difference narrows if you brief GPT-5.5 more explicitly, but in production, the model that requires less hand-holding produces faster, more reliable outputs. We cover why this matters in our guide on how to get procurement teams to adopt AI.
Where both models fall short is the same: genuine programme judgement. What your liability cap should actually be, which markets are wave one, what your real integration inventory looks like, what AI governance positions you are prepared to commit to contractually. No model answers those questions for you. Those are human decisions.
Our recommendation
For production procurement workflows, Claude Opus 4.7 is the model we would deploy today. It produced a document that could go to vendors with targeted edits rather than wholesale rewriting. It handled commercial structure, legal terms, multi-country specificity, and vendor qualification at a level that GPT-5.5 did not reach in this test. On the dimensions that matter most in a real sourcing process, the gap was consistent and material.
GPT-5.5 has a role. Its scoring methodology transparency, functional requirements matrix, and KPI framework are stronger. If you merged Claude Opus 4.7's programme-specific framework with GPT-5.5's appendices, you would have a genuinely excellent document. But that merge requires someone who can evaluate both outputs dimension by dimension, with judgement that neither model can replicate.
The takeaway for CPOs: these flagship models are now fast enough to produce a credible first draft of complex sourcing documents in under a minute. The value is not in the speed. The value is in spending your saved time being more rigorous about what is actually in the document, and choosing the model that gets you closest to a final output with the least rework.
Frequently asked questions
Can AI draft a ready-to-issue enterprise RFP?
It depends on the model and the brief. In our test, Claude Opus 4.7 scored 85.1/100 and produced a document with specific programme parameters, a paired pricing pack, and enforceable commercial terms. GPT-5.5 scored 66.9/100 and produced a well-structured template with placeholder data throughout. The quality of AI RFP output is bounded by the context you provide.
Which AI model is best for procurement RFP drafting?
Based on our comparison, Claude Opus 4.7 outperformed GPT-5.5 on vendor qualification, technical architecture, commercial evaluation, SLAs, legal terms, and multi-country coverage. GPT-5.5 won on scoring methodology transparency. The ideal approach is AI for structural first drafts with human judgment on commercial schedules, liability terms, and market-specific requirements.
What are the risks of using AI to draft procurement RFPs?
The primary risk is surface credibility: AI-generated RFPs look polished but may contain placeholder data, vague commercial terms, and missing enforcement mechanisms. This produces non-comparable vendor bids, extended legal negotiations, and overpriced submissions loaded with risk premium.
Where should procurement teams use AI in the RFP process?
AI excels at first drafts of structural sections, ingesting and comparing supplier responses, drafting clarification questions during evaluation, and modelling TCO scenarios. It should not be used to write final commercial schedules, liability terms, market-level requirements, or qualification gates without expert review.
Molecule One is an AI-native procurement consultancy. We help CPOs and procurement leaders deploy AI with measurable ROI, working workflows, and teams that actually adopt them. Start with a free AI Readiness Assessment.