Claude Opus 4.7 for Procurement Teams: A Smarter Model That Expects More From You
We ran 5 real procurement workflows head-to-head against Opus 4.6. Here's what the benchmarks won't tell you.
4.7 is the better model. That said, read the small print.
Opus 4.7 dropped yesterday. We ran it the same day, five procurement workflows back to back against 4.6: RFP scoring, contract redlining, spend analysis, category strategy, and supplier performance reviews. 4.7 won four of the five, scored 183 out of 200, and beat its predecessor by 15.5 points. For analytical procurement work, it's the right call.
But there's a personality shift in this model that will catch teams off guard if they just drop it into existing workflows. 4.7 is more literal, more analytical, and less willing to infer what you want. Prompts that worked beautifully with 4.6 will produce different outputs. Not worse, just different in ways you need to understand before you flip the switch. We'll walk through all of it.
"4.7 feels like what happens when a model stops trying to be helpful by anticipating what you want, and starts being helpful by actually doing what you asked."
After five workflowsFour things that actually changed
Before the numbers, here's a plain-language summary of what Anthropic shipped. Some of these are capability upgrades, some are behavioural shifts. The behavioural ones are the ones most likely to affect your day-to-day.
The headline numbers from the release
Before we get into our own testing, here's what Anthropic published. These are their numbers, on their benchmarks.
Source: Anthropic, "Introducing Claude Opus 4.7" →
Most of these are coding and agentic benchmarks, which is where Anthropic has focused the release messaging. What we wanted to know is whether the same improvements translate to procurement work specifically: document analysis, contract review, spend data, category strategy. That's what we tested.
One claim that does show up in our results: the 21% fewer errors on document work. We saw this in practice with the self-verification behaviour, which we'll cover in a moment.
How both models scored across 5 use cases
Each use case was scored across four dimensions (accuracy, self-consistency, output quality, instruction-following), each 0-10, for a maximum of 40 points per test. How we scored this →
| Use Case | Opus 4.6 | Opus 4.7 | Winner |
|---|---|---|---|
| UC1: RFP Analysis & Supplier Scoring | 36.0 /40 | 35.5 /40 | 4.6 |
| UC2: Contract Redlining & Risk Extraction | 34.0 /40 | 36.0 /40 | 4.7 |
| UC3: Spend Analysis & Category Intelligence | 32.5 /40 | 37.0 /40 | 4.7 |
| UC4: Category Strategy & Sourcing Plan | 34.0 /40 | 37.0 /40 | 4.7 |
| UC5: Supplier Performance Scorecard (QBR) | 31.0 /40 | 37.5 /40 | 4.7 |
| Total | 167.5 /200 | 183.0 /200 | 4.7 |
4.6 held its ground in UC1 (RFP scoring) largely on presentation quality. It produced richer, more polished formatted outputs without being asked. In the four tests where the quality of analysis was the deciding factor, 4.7 pulled ahead cleanly. Expand each use case below for the full breakdown.
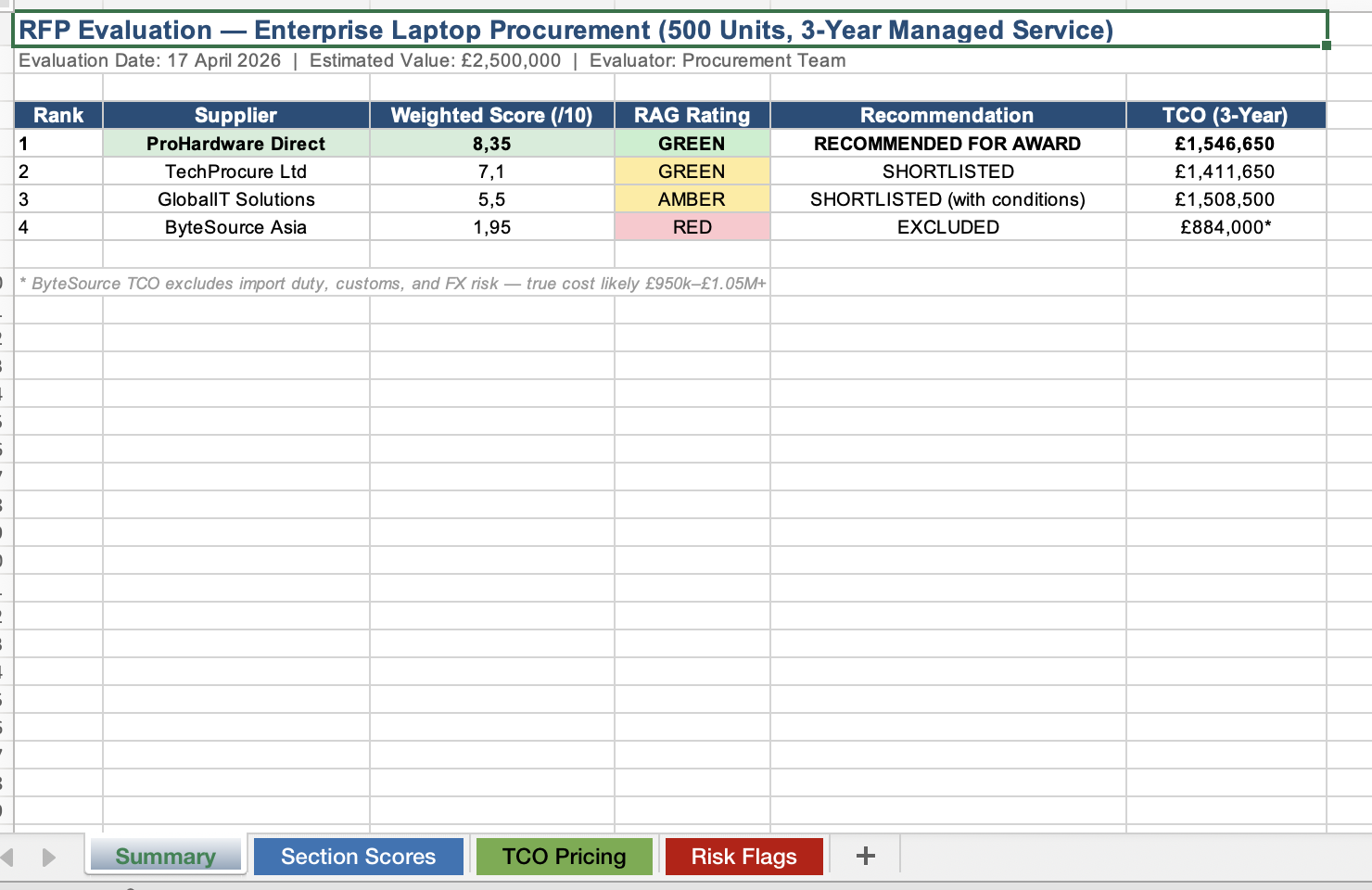
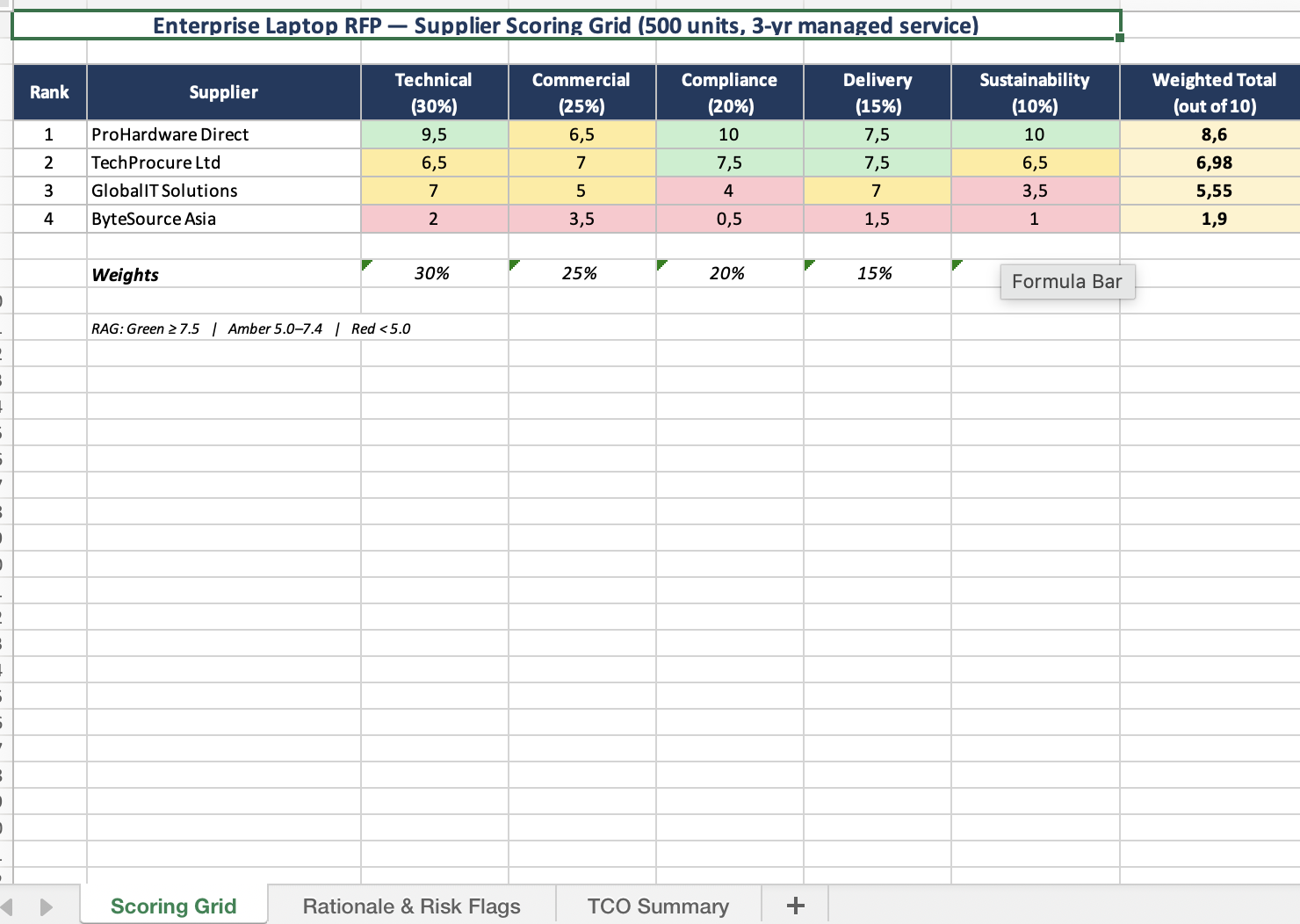
Four supplier responses for an Enterprise Laptop Procurement (500 units, £2.5M, 3-year managed service). We embedded a spec-level trap: one supplier quoted the Dell Latitude 5540 in their executive summary but specified an incompatible processor in the technical section.
Both models caught the obvious issues. Where 4.6 stood out was in what it produced: RAG colour coding, a 4-tab Excel scorecard, longer rationale columns written for a non-expert audience. You could hand it straight to a stakeholder without editing. 4.7 gave sharper, more expert-readable rationales and actively revised two supplier scores during its self-check loop, though the 3-tab Excel was simpler and the overall output needed more formatting work to reach the same polish.
The most telling detail: the prompt didn't ask for a formatted output document. 4.6 produced one anyway. 4.7 gave text. That pattern ran through almost every test.
A fictional IT services contract with 9 deviations from standard terms and 4 internal inconsistencies, including a Scotland vs England & Wales governing law mismatch, a 1x vs 2x liability cap, and a 180-day termination notice where the standard is 30 days.
Both models found all 13 issues. The scoring came down to how they communicated them. 4.7 quantified impact: "6x liability cap gap," "6x termination gap." 4.6 described the same issues qualitatively: "liability cap too low," "notice period too long." For a Finance Director making a commercial call, 4.7's framing is more useful; you can take it straight to a decision without recalculating.
4.7 also got the risk severity right where 4.6 didn't. The Scotland/England & Wales governing law issue was rated HIGH by 4.7, MEDIUM by 4.6. The jurisdiction distinction affects litigation venue, applicable precedents, and enforcement. It's a high-stakes flag, and 4.6 undersold it.

A 20-row spend dataset across 12 sub-categories with a deliberate £200,000 arithmetic error baked in; the stated total didn't match the actual sum of the rows. Both models caught it, but handled it very differently.
4.7 flagged the discrepancy before running any analysis, stated it would use the corrected £12.735M baseline, and asked for confirmation before proceeding. 4.6 spotted it too, but buried it as a footnote in the data table and carried on with the analysis on the wrong total. In a live context, a footnote gets missed; a hard stop before analysis starts does not. Every savings figure downstream from 4.6's run was built on an incorrect number.
4.7 also ran supplier deduplication (19 unique suppliers across 12 sub-categories (4.6 didn't surface this)) and correctly classified Waste Management as a Bottleneck category rather than Leverage, picking up the supply-side risk that makes waste a harder category to switch than the textbook answer suggests.


A 12-month Marketing Services category strategy for a European retail chain: €20M spend, 5 markets, 12 product launches, 40+ fragmented agencies. Complex enough that the quality of analysis would show clearly.
Both covered all required sections. The difference was in what sat inside them. 4.6's risk flags were category-level: "product launch disruption." 4.7 named the chain: "agency failure mid-campaign → financial distress / talent attrition / key person dependency." One is something to worry about; the other is something you can build monitoring around.
The sustainability section was the starkest contrast. 4.6 covered FSC certification and Scope 1/2 disclosure. 4.7 cited the UK CMA Green Claims Code, the EU Green Claims Directive 2026, Ad Net Zero framework alignment, FSC stock, vegetable-based inks, modular reusable event builds, and post-event waste diversion reporting. None of it was prompted. It wrote like someone who has managed this category before.
One area where 4.6's answer may be more realistic: agency panel size. 4.6 recommended 8-12 agencies across 5 markets. 4.7 said 2-4 per sub-category. 4.7's number is more commercially aggressive; 4.6's is easier to actually operate across five markets. Worth pressure-testing against your own context.

A full-year QBR pack for a fictional packaging supplier, covering four quarters of OTIF, quality incidents, invoice disputes, and non-conformance data, with an explicit scoring formula. Largest margin of the five tests.
4.6 made a clean factual error: every improvement action was dated June 2025 in a document dated April 2026. That's the kind of thing a supplier will notice immediately, and it undermines everything else in the pack. 4.7 got the dates right, and its self-check section went further than any other test: it reconciled all KPIs back to the source tables, flagged Q4 OTIF as a borderline vulnerability (+0.1pp above target), marked the Responsiveness score as an estimate rather than verified data, and caught a mathematical observation in the Q1 figures. That's analyst-level quality control, not a formality.
One genuine point for 4.6: it chose PowerPoint for the QBR output, which is the right format for a supplier meeting. 4.7 chose Word + Excel, which is more rigorous but not what you'd take into a room. 4.6 also did something we liked: it asked for format confirmation before generating the pack. The user skipped it, which contributed to the errors, but that consultative check is good practice in real workflows.
4.7 does what you say. Not what you mean.
This showed up in every single test. Opus 4.6 would look at a prompt, infer the likely intent, and deliver a polished version of what it thought you wanted, cover page and all. Opus 4.7 reads what's in the prompt and executes that, nothing more. If you didn't ask for a Word document, you don't get one.
That's not a regression. It's a deliberate shift toward predictability. But it means prompts that relied on 4.6's inference (and plenty do, even ones never written with that in mind) will need updating.
Go through your highest-frequency prompts and add explicit output format instructions. What you had to imply with 4.6, you now need to state with 4.7. It's a one-time prompt rewrite, and once it's done the behaviour is actually more consistent.
The flip side: the energy 4.6 spent inferring your intent has clearly gone somewhere more useful. 4.7 thinks harder before it writes, and it shows.
The self-check is real this time
4.7 has a built-in verification loop that runs before it presents output. We watched it work in three of the five tests: it revised two supplier scores mid-check in UC1, stopped to verify the spend total before analysis in UC3, and produced a dedicated reconciliation section in UC5 that caught a borderline OTIF result we hadn't specifically flagged.
This is different from 4.6's approach. 4.6 included self-check sections in some tests, but they were mostly declarative: the model stated it had checked without showing any evidence of what it had actually reviewed. 4.7's checks are visible and they produce changes.
If you've been adding "verify your calculations before presenting" or "run a consistency check" to your prompts, you can take those out now. 4.7 runs this automatically. Depending on how many of your prompts carry that instruction, removing it saves tokens and keeps things cleaner.
Deeper domain knowledge, applied without prompting
The clearest upgrade in 4.7 is domain depth. Across multiple tests it applied specific, current knowledge (regulations, market participants, sub-category practices) that 4.6 either missed or covered at a much higher level. And in no case were we prompting for this detail. It just appeared.
Risks that tell you something
Across UC2 and UC4, 4.6 produced flags like "product launch disruption" and "governing law risk." Technically correct. Analytically thin. 4.7 produced: "agency failure mid-campaign → financial distress / talent attrition / key person dependency." You can write an early warning indicator around that. You can't do much with "product launch disruption."
Sustainability as a category expert, not a checklist
In the Marketing Services category strategy, 4.7 cited the UK CMA Green Claims Code, the EU Green Claims Directive 2026, FSC stock, vegetable-based inks, Ad Net Zero, modular reusable event builds, and post-event waste diversion reports. 4.6 hit FSC and Scope 1/2. Neither was prompted for this level of detail. 4.7 wrote like someone who has actually managed this category before.
Numbers over labels
In the contract test, 4.7 translated every risk into a business impact figure. A liability cap issue became a "6x liability cap gap." A termination clause became a "6x termination gap." 4.6 named the same issues without quantifying them. The first version gives a Finance Director something to work with; the second gives them homework.
Sharp and strategic, but not always what you need
4.7 writes in a consulting register: tight, executive-ready, minimal padding. Its executive summaries are strong: the kind of thing you could paste into a board paper without editing. It uses bullets where they add value rather than as a default structure. It doesn't recap its methodology at the start of every section.
4.6 is more narrative and more accessible. Its longer rationales are useful when the audience needs to follow the logic rather than just read the conclusions. For stakeholder communications, non-expert audiences, or anything that needs warmth alongside analysis, 4.6 still reads better.
4.7 for exec summaries, strategy briefs, category plans, risk assessments, anything going to a decision-maker who wants conclusions fast.
4.6 or Sonnet for creative writing, supplier relationship content, stakeholder communications, or any document written for a general audience. 4.7's consulting tone can feel cold when connection matters more than precision.
Where to switch, where to stay
Will it cost more to run?
We didn't run API-level token counts in this evaluation; testing was done through the Cowork and Claude.ai interfaces. So treat this section as informed estimation. Pricing for both models is identical at $5/$25 per MTok input/output, so the question is purely about volume.
Anthropic's guidance suggests 4.7 at effort: xhigh could use up to 30% more tokens than 4.6 at effort: high, due to extended thinking and the self-verification pass. Our estimate is real-world overhead sits closer to 15-20% initially, for a few reasons.
4.7's outputs are tighter: shorter prose, less methodology recap, fewer filler paragraphs. It may think longer but it writes less. The built-in self-check also removes a reprompt loop: if you were previously running a separate "check your work" prompt, that's gone now. And 4.7 tends to get to the right answer in one shot, which matters. Cheaper-per-token models that need three rounds of refinement often end up costing more overall, plus the time you spend on those rounds.
As teams learn to write proper prompts for 4.7 (explicit format instructions, tighter specs) we'd expect the overhead to normalise toward 4.6 levels. The extra cost right now is largely the cost of adapting.
PDF and table reading: 4.7 is supposed to be meaningfully better at complex PDF structures and multi-table documents (3x the image resolution, per Anthropic) but we didn't get to test this. It's on the list for the next issue.
API-level token counting: The token analysis above is qualitative. A proper API-level comparison with matched prompts is in progress.
A strong step forward, and a bridge to whatever comes next
4.7 is the better model for procurement analytics. The self-verification, the domain depth, the risk calibration: these are real improvements that show up in outputs you'd actually use.
It also feels like a model in transition. The prompt-literalism and the formatting restraint suggest something that is being pushed in a deliberate direction and hasn't fully settled there yet. Our read is that the next major release will smooth some of these edges. For now, 4.7 is what you want for anything analytical. Hold on 4.6 for writing and presentation work, update your prompts before you flip the switch, and don't mistake the formatting plainness for a lack of capability. The analysis underneath is genuinely better.
If you're deciding which AI tools to deploy across your procurement function, not just which model to use, but which workflows to start with and how to build team adoption, that's exactly what we work through with clients. See our 12 AI use cases in procurement that actually work, or start with our AI Readiness Assessment to understand where your team stands today. And if you're evaluating the consulting vs. software question, this article lays out an honest framework.
4.6 vs 4.7 at a glance
| Dimension | Opus 4.6 | Opus 4.7 |
|---|---|---|
| Output format | infers Produces polished docs unprompted | literal Delivers exactly what the prompt specifies |
| Self-verification | declarative States it checked; rarely shows revision | active Revises scores, flags errors, shows its work |
| Domain knowledge | Category-level, solid but surface | deep Named regulations, sub-category specifics |
| Risk framing | Category-level: what to worry about | mechanism Causal chains: what to monitor and do |
| Writing register | Narrative, accessible, good for general audiences | Consulting-style, tight, exec-ready |
| Data handling | Flags issues quietly; proceeds on stated data | pre-checks Stops and verifies before analysis starts |
| Execution mode | consultative Asks for confirmation on complex tasks | autonomous Executes and delivers on its own assumptions |
| Prompt requirement | Infers context; tolerant of loose instructions | explicit Format instructions must be stated |
Approach
Five self-contained prompts were developed using synthetic procurement data (fictional suppliers, spend figures, and contract terms created specifically for this evaluation). Each prompt was run identically in two separate sessions: Claude Opus 4.6 at effort: high and Claude Opus 4.7 at effort: xhigh. Outputs were scored independently across four dimensions for a maximum of 40 points per use case and 200 points overall.
Where possible, output files were read programmatically and compared against source data. Arithmetic was verified independently in Python where discrepancies were suspected.
Scoring Dimensions
| Dimension | What was assessed | Max |
|---|---|---|
| Accuracy / Completeness | Coverage of all required elements; correct facts, calculations, and references; detection of embedded data traps | 10 |
| Self-consistency | Internal agreement between numbers, scores, and narrative; evidence of self-check execution | 10 |
| Output quality | Usability without further editing; actionability for the intended audience (CPO, CMO, Finance Director) | 10 |
| Instruction-following | All numbered steps completed; format requirements met; no required elements missed | 10 |
Caveats
Skill contamination (UC4 and UC5): Both use cases were run in a Cowork environment with active skills: category-strategy-builder for UC4 and supplier-scorecard-engine for UC5. Some document structure and section content in both outputs was influenced by skill prompting. Instruction-following scores were adjusted upward accordingly. Analytical content was scored independently and is unaffected.
Synthetic data: All supplier names, spend figures, contract terms, and performance data are fictional. Results reflect model behaviour on these scenarios and should not be read as real supplier performance.
No API token counts: Token counts were not captured via the API. Relative verbosity was noted qualitatively. The token section of this article is an estimate based on observed output length and Anthropic's published guidance.
Single-run results: Each use case was run once per model. LLM outputs have inherent variability; a different run on the same prompt could produce a different score within a reasonable range. The patterns we observed were consistent enough across five tests to draw conclusions, but treat individual use case scores as directional rather than definitive.
Molecule One builds AI-native procurement tools for mid-market and enterprise buyers. We help procurement teams deploy and get measurable value from AI in the workflows you run every day, not just in theory.
Issue #001 · April 2026 · sk@moleculeone.ai · moleculeone.ai